mozaic.fm ep73がセマンティックウェブの回で、あの神崎さんが出ていた。そこでSPARQLの話をしていて、個人的に盛り上がったのでちょっと遊んでみた。ポッドキャストの感想に代えて。
Rust製のOxigraphというSPARQLサーバー実装があったので1、これを立ち上げて、Rubyからデータを挿入し、ウェブUIでクエリーする、というのをやってみる。
サーバーの用意
サーバーはDockerイメージがあるし、Rust環境があればcargo install oxigraphで簡単に入るんだけど、データの挿入とかの機能が最近入った物で、まだリリース版には取り込まれていないので自分でビルドした。データベースファイルを置く為のディレクトリーとして/tmp/oxigraphを指定しながら起動する。
% ./target/debug/oxigraph_server -f /tmp/oxigraph
http://localhost:7878 でサーバーが立ち上がり、ウェブUIもあるのでブラウザーでアクセスできる。
RDFの用意
RDFとしては、ポッドキャストの終わりの方でも触れられていたウェブアノテーションを使ってみよう。
ウェブアノテーションは、ウェブ上のコンテンツに何らかの注釈をつけるための仕様で、RDFで定義されているから目的に適うし、JSONでの記述が推奨されているから馴染み易い。例えばこうなる
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "https://gitlab.com/-/snippets/2026980/raw/master/annotations.jsonld",
"type": "AnnotationCollection",
"label": "mozaic.fm's annotations",
"total": 2,
"first": {
"id": "https://gitlab.com/-/snippets/2026980/raw/master/annotations.jsonld#first",
"type": "AnnotationPage",
"startIndex": 0,
"items": [
{
"id": "https://gitlab.com/-/snippets/2026980/raw/master/mozaicfm-annotates-sparql.jsonld",
"type": "Annotation",
"body": {
"source": {
"id": "https://files.mozaic.fm/mozaic-ep73.mp3",
"type": "Audio",
"format": "audio/mpeg"
},
"purpose": "commenting",
"selector": {
"type": "FragmentSelector",
"conformsTo": "http://www.w3.org/TR/media-frags/",
"value": "t=00:58:57,01:21:24"
}
},
"target": "http://www.wikidata.org/entity/Q54871"
},
{
"type": "Annotation",
"body": {
"id": "https://mozaic.fm/episodes/73/semantic-web.html",
"purpose": "describing"
},
"target": "https://files.mozaic.fm/mozaic-ep73.mp3"
}
]
}
}
RDFやJSON-LDの説明は省くけどウェブアノテーションの部分の説明をするとこう:
- これはアノテーションのコレクションである
- 中には二つのアノテーションがある
- 一つ目は、
- SPARQL(
http://www.wikidata.org/entity/Q54871)へのコメントで、 - その内容は
https://files.mozaic.fm/mozaic-ep73.mp3という音声にある。 - 音声の範囲は00:58:57から01:21:24まで。2
- SPARQL(
- 二つ目は、
https://files.mozaic.fm/mozaic-ep73.mp3という音声の説明で、- その内容は
https://mozaic.fm/episodes/73/semantic-web.htmlにある。
となっている。schema.orgなんかと同じJSON-LDを使う。
データの挿入
これをOxigraphに入れてみよう。Oxigraphはエンドポイントを分けていて、
/... ウェブUI、及び単純なデータ挿入/query... クエリー/update... (使用に則った)データ挿入や削除などの更新系操作
で、今回の挿入には最後のを使う。Ruby製のSPARQLクライアントを使おう。
require "json/ld"
require "sparql/client"
ENDPOINT = "http://localhost:7878/update"
annotation = JSON.load(File.open("./annotations.jsonld"))
data = RDF::Graph.new
# JSONのデータを抽象的なRDFモデルに変換
data << JSON::LD::API.toRdf(annotation)
sparql = SPARQL::Client.new(ENDPOINT)
# クエリーにはSPARQL言語とTurtleなどのデータ表現が使われるけど、
# ライブラリーがRDFモデルからいい感じに組み立ててくれる
sparql.insert_data(data)
% ruby ./load.rb
とやると、データが取り込まれる。
SPARQLクエリー
Oxigraphは(他の多くのSPARQL実装と同様)ウェブUIでSPARQLクエリーを試せる。とりあえず全件取り出してみよう。
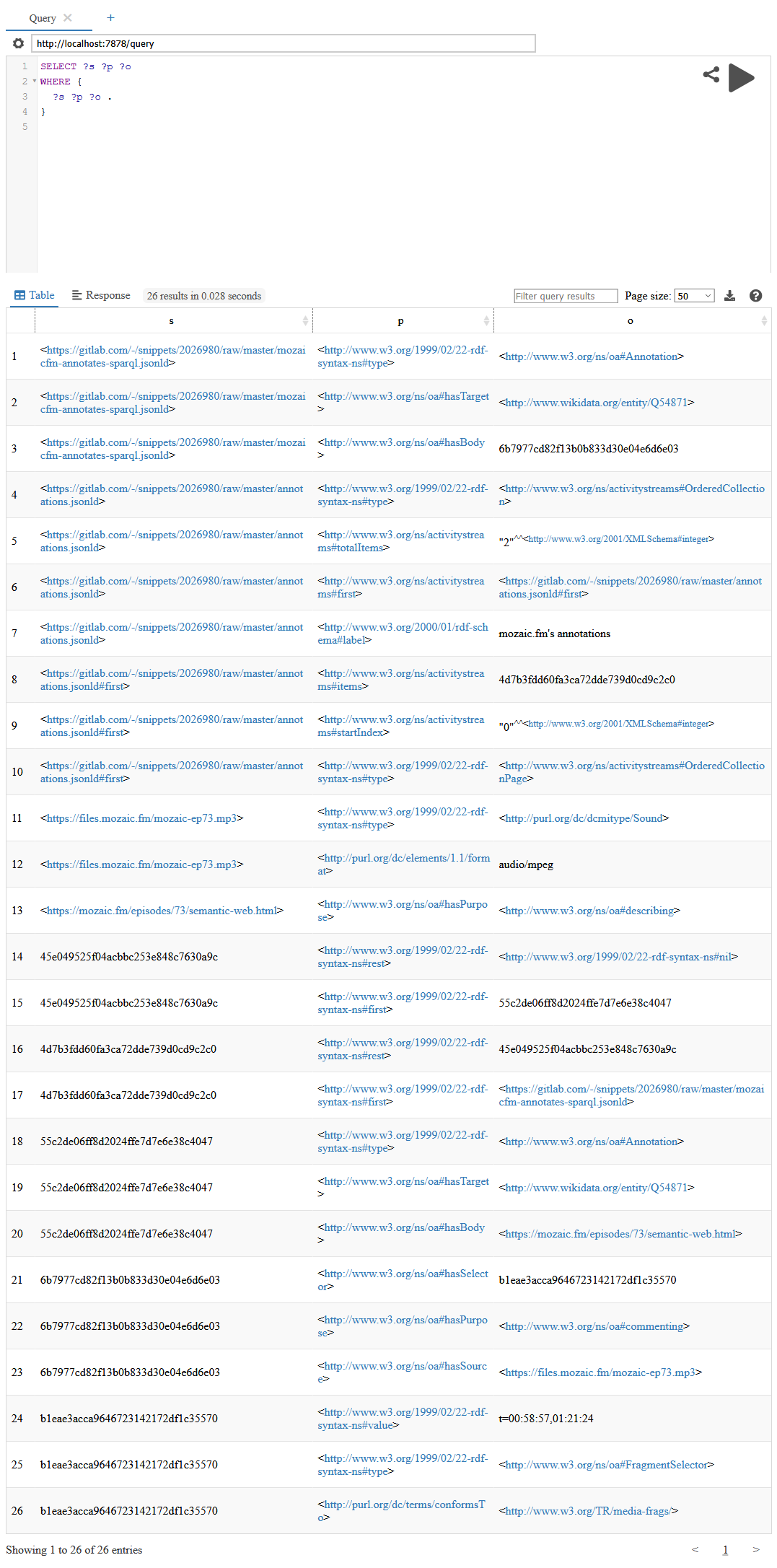
(こういうのもIPythonとかIRubyで貼れると嬉しいなあ……) 上のウェブアノテーションから26トリプルが作成されたのが分かる。
「誰かSPARQLについて話してないかな~?」という時には述語(predicate)が「hasTarget(ウェブアノテーションで、アノテーション対象になっているという関係を示す)」、目的語(object)が「Q54871(wikidata.orgでのSPARQLを示すID)」になっているような物を検索してやればよい。
PREFIX wd:<http://www.wikidata.org/entity/>
PREFIX oa:<http://www.w3.org/ns/oa#>
SELECT ?s ?p ?o
WHERE {
?s oa:hasTarget wd:Q54871 .
}
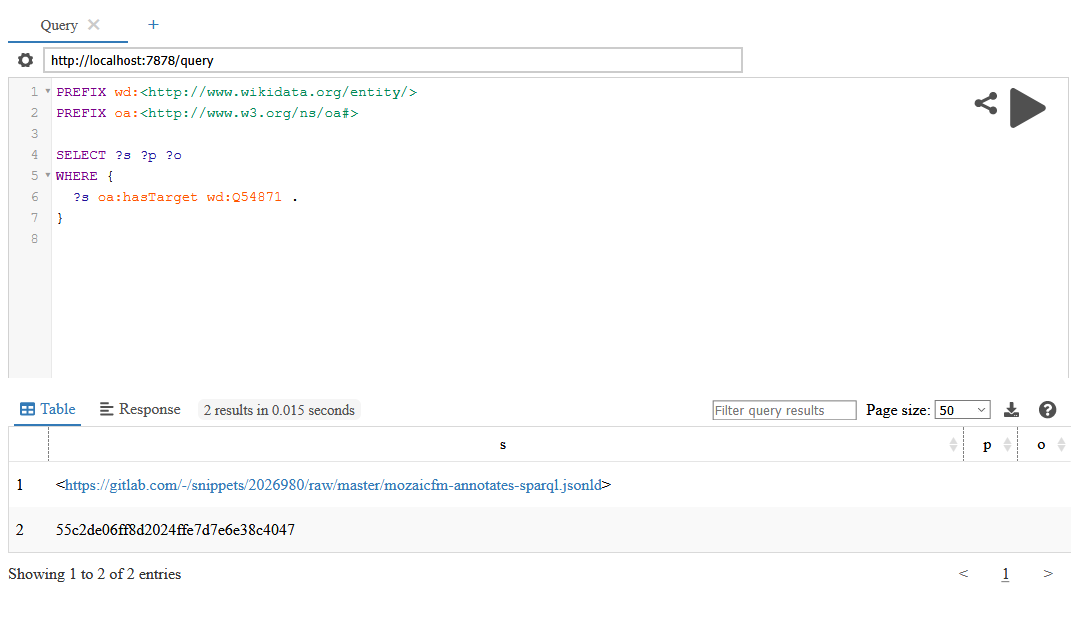
「55c2de06ff8d2024ffe7d7e6e38c4047って意味が分からんな?」って思ったら、それを主語(subject)にして検索すれば概要が掴める(かも知れない)。のだけどそれのやり方は分からなかったので誰か教えて……。
最後ケチが付いた感じだけど、こんな感じでSPARQLデータベースを動かすことができる。Oxigraphはwikibaseモードも用意しているので、読書メモとかをwikibaseに取っていって、それをOxigraphをフロントエンドんにしてクエリーするのもいいかもなあ。読書メモだと、メモその物はグラフの末端になるだろうけど、そのターゲットである本についての情報はSPARQLエンドポイントを提供するに値するはずだ。
なんと、やはりポッドキャスト中で触れられていたwikidata.orgの実装であるoxigraph-wikibaseまである。
t=00:58:57,01:21:24というのはMedia Fragment URIという仕様での時間指定の仕方。余談だけど、これをパースするJavaScriptライブラリーを作っているから見てみておくれ: Media Fragment URIのJavaScript(TypeScript)実装をリリースした

Comments
No comments yet. Be the first to react!