
C’est une tentative d’écriture rapide de billet de blog sur Plume. Ça devrait être plus court que d’habitude et moins travaillé, dans l’idée de partager plus d’idées.
Tout a commencé avec un article de 2017 intitulé Energy Efficiency across Programming Languages qui présentait une liste des langages les plus efficients en terme d’énergie, sous-entendu l’énergie consommée par l’ordinateur qui exécutera la logique décrite dans le langage donné. Et l’article se termine sur le tableau récapitulatif suivant, donnant grand gagnant des langages comme C, C++, Rust, Ada, Java, etc.
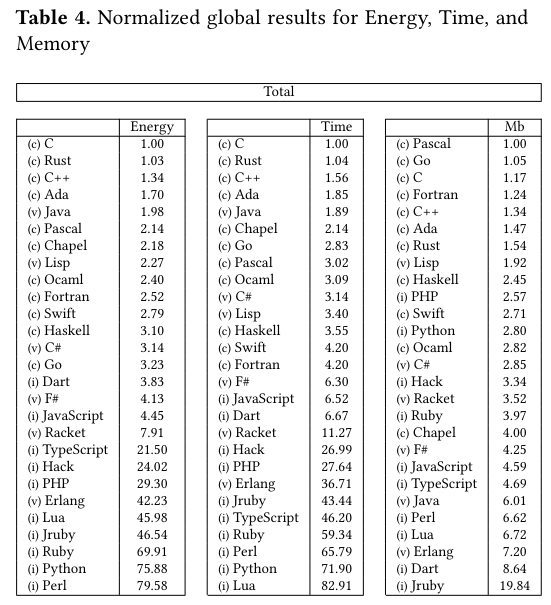
Parce que c’est un travail scientifique, au delà des résultats, il faut bien sûr discuter les conditions expérimentales. En effet, pour avoir lu un ou deux papiers de ce domaine, c’est souvent là où il y a les infos importantes, bien plus que dans les résultats. Et vu qu’on s’intéresse à la consommation d’énergie par un ordinateur, c’est intéressant de comprendre comment cet ordinateur est conçu. On ne connaîtra pas le modèle exact, les auteurs ne le spécifiant pas, on apprend juste que c’est un ordinateur portable avec 16Go de RAM et un processeur Haswell Intel(R) Core(TM) i5-4460 CPU à 3.20GHz. Probablement un PC portable pro des années d’environ 2013, allez donc voir mon guide pour choisir son PC portable où je parle de cette gamme de PC si vous ne l’avez pas encore lu. Ensuite, on peut s’intéresser à l’environnement logiciel de nos tests : aujourd’hui nos applications ne s’exécutent jamais seules sur un ordinateur, mais en “compétition” et en “collaboration” avec les autres, et donc tout cet écosystème a un impact sur les mesures, ici on apprend simplement que c’est un Ubuntu 16.04. Notons aussi qu’un langage n’est qu’une façon de formaliser de la logique, il faut encore traduire cette logique en instructions pour le CPU via un compilateur ou un interpréteur ; parfois pour un langage plusieurs interpréteurs et compilateurs sont disponibles. Enfin, on mesure pas le langage directement, mais des programmes écrits dans ce langage ; se pose donc la question de quelle réalité dépeignent les programmes choisis.
Tous les points abordés précédemment sont largement ignorés dans le papier : on aurait pu tester avec des architectures processeurs différentes (ARM, RISC V, SPARC, etc.), avec des systèmes d’exploitations différents mais aussi plus contrôlés (un build maison de Linux), voir l’impact du compilateur pour un langage donné, et essayé de quantifier la représentativité des programmes de test vis à vis de certains usages de l’informatique.
Mais finalement, tout ce que je présente avant, ce ne sont que des méthodes, des fabrications mentales qui cachent le problème principal : aborder la consommation d’énergie et les performances à travers le concept de langage n’est pas pertinent. Bien sûr, vous pourrez trouver des corrélations, dire que Python est plus intensif en ressource que C, et vous pourrez même vous convaincre qu’il y a causalité : parce que Python ne déclare pas la gestion de la mémoire à la main, parce que le système de type est dynamique, etc.
Tout ça d’ailleurs ne tient que si on suppose que votre programme est intensif vis à vis des paramètres considérés, c’est à dire CPU et RAM, qui sont loin d’être les seuls goulots d’étranglement sur un système informatique. D’ailleurs, dans beaucoup d’applications dans l’industrie, c’est les entrées/sorties qui sont le facteur limitant (par exemple la bande passante réseau). Donc en gros, le problème principal rencontré par un des plus gros consommateurs d’énergie en informatique, n’est pas considéré. Je me souviendrai toujours de Walmart qui disait en 2013 être passé de 30 serveurs à 3 le jour du Black Friday en passant de Java à Javascript (Node.JS), soit une intuition complètement contraire à celle des résultats proposés par le papier de recherche. Non, le black friday n’en est pas plus vert.
Mais encore une fois, ce n’est pas le bonne façon de formuler le problème, car ça n’a rien à voir avec le langage lui-même. En python on peut allouer la mémoire à la main, des compilateurs qui nécessitent des types statiques existent en python comme en ruby, etc. Dans notre cas de Node.JS, c’est bien moins le langage, Javascript, qui est important, que les intentions portées par son interpréteur et sa bibliothèque standard : Node.JS : toutes vos entrées/sorties seront asynchrones via un modèle événementiel, choix de conception rendus possible par le noyau Linux et son API epoll. Tout ces points sont complètement indépendants du langage. Vous pouviez dès 2013 coder en quelques centaines de ligne un modèle à base de coroutine et de boucle événementiels en Python. Et vous allez me dire, oui mais ce n’est pas comme ça que Python est utilisé normalement.
On arrive donc à ma thèse : s’intéresser au langage, c’est vraiment se situer au pire niveau d’abstraction possible. En se rapprochant du matériel, on peut discuter des optimisations de compilateur, de gestion de mémoire, des abstractions fournies par votre système d’exploitation, bref de plein de trucs pertinents qui ont un impact réel et direct sur les performances. En se rapprochant de l’humain, on peut s’intéresser à la cible d’un langage, à celles et ceux à qui il s’adresse, à la classe de problèmes sur laquelle il est positionné, à leur démographie, aux conditions de production du code, aux objectifs poursuivis, à l’effet rebond, à ce que suggère comme usages l’API et la documentation du langage et de ses bibliothèques, etc. Et là on pourrait noter que Python est d’abord orienté vers les débutant·es, vers la facilité d’utilisation, acceptant en retour de donner moins de contrôle sur comment doit s’exécuter la logique, et accéder à ce contrôle est parfois moins naturel que dans des langages prévus pour.
Le pire, c’est qu’on peut continuer comme ça pendant des années, à produire de la recherche sur le sujet, avec tous les outils de la respectabilité scientifique du monde. Et les résultats ne seront pas faux en soit, juste inutiles. Pour faire une analogie, c’est comme si on s’intéressait à faire évoluer la largeur des places de stationnement dans la ville pour étudier le niveau de pollution. On pourrait constater des corrélations : quand on réduit, on voit un peu moins de SUV, mais faut faire attention à l’effet rebond : les SUV se garent sur deux places parfois, c’est du à un manque de X ou Y, etc. Et puis comme ça, de fil en aiguille, entasser tout un tas de littérature sur le sujet, pour être bien certain qu’on ne prenne jamais la question de l’automobile en ville sous un angle plus politique (nous on a des données statistiquement correctes sur la taille des stationnement, OK l’obscurantiste ?!).
D’ailleurs, je crois que cette obsession pour les langages de programmation, source de toute réussite, cause de tout échec, participe aussi à notre aveuglement sur les possibilités réelles des ChatGPT et autres modèles de langage. À partir du moment où on reconnaît en informatique que l’environnement et matériel est important d’une part, et que l’interaction avec l’humain est un facteur important d’autre part, il faudrait être capable de fournir ces informations à votre modèle. En élargissant, on peut dire que le travail d’un·e développeur·euse, c’est bien moins d’écrire des lignes de code, que de comprendre l’environnement métier ET technique de son sujet. Si on veut faire de la programmation plus sobre, il va falloir donner du contrôle tant sur l’aspect métier (qu’est ce qu’on a vraiment besoin de faire) et sur l’aspect technique (comment on intéragit avec l’ordinateur) aux développeur·euses. Et donc il faudra aussi du temps pour comprendre les enjeux de sobriété, apprendre à contrôler plus finement l’ordinateur, et écrire cette logique de contrôle plus fine. Ce qui veut dire que vous allez devoir faire le travail quoiqu’il arrive, coder ne serait plus que formaliser votre compréhension du sujet…

Comments
No comments yet. Be the first to react!